
Incomparable data sets, cherry-picking, and dubious statistical analysis are behind the claims of robust employment growth. Only 1.4 million jobs were added in 2017.
Surjit Bhalla has invented an estimate that 15 million jobs were created in 2017 (‘Robust job growth, not fake news,’ IE, April 28). This is an invention; it is not a discovery or an inference by honest statistical analysis. It is an invention because Bhalla unnecessarily patches selective estimates of two completely incomparable sources of data on employment. Note that the two sources are completely incomparable and the patches are of cherry-picked data — apparent selections of convenient estimates from two different sources.
Further, there is no compelling reason to be so selective because both sources provide complete data to draw independent inferences.
Bhalla presents data on two age groups — 15-24 years and 25-64 years. He has chosen to disregard people of 65 years and above although 16 million of these were employed during early 2016. So, we have two age groups — 15-24 and 25-64 years. The stated reason for this division is because, “when you have increased enrolment in education … employment (and labour force) definition should include the fact that you are attending school or college’’.
I don’t get that reasoning. It is more likely that the division is just the convenient one to get the desired results.
CMIE provides data on employment by age-brackets in its “Statistical Profile”, which is released after the completion of every wave of its Consumer Pyramids Household Survey (CPHS). Data from six such waves are freely available at http://unemploymentinindia.cmie.com. There are 10 age brackets of five years each from 15-19 through 60-64 and then there is an 11th age bracket of greater than 64 years age.
Bhalla picks data for the age groups 25-64 from here and ignores the data on the age-groups 15-24 and greater than 64 years. Why were these age brackets picked and why were the others not? This was cherry-picking of selective data that suits the objective of the author.
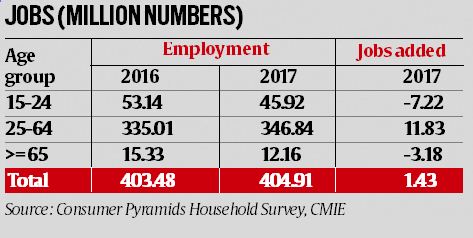
As is clear from the table, jobs were added in the age bracket 25-64 years. But, jobs were lost in the age brackets 15-24 years and greater than 64 years. These age brackets have been omitted by the author. The CPHS data shows that jobs grew by 1.4 million in 2017 and not 15 million, as claimed by Bhalla.
If all the data is available in CMIE’s CPHS database, why was it necessary to patch the data with the EPFO data? This question is pertinent because the two sources are not at all comparable. The EPFO data pertains to only about 15 per cent of India’s labour force. The Economic Survey had estimated 60 million to be registered in EPFO. Compare this to over 400 million persons employed in the country.
So, the EPFO data used for the age group 15-24 is seriously partial. It is possible that the rise in employment in this partial dataset is offset by greater decline in the full dataset of all persons in the 15-24 age bracket. This is what CMIE’s CPHS data suggests.
An increase in EPFO registration does not necessarily mean increase in employment. These data reflect the substantial formalisation of the labour force happening around now. Old jobs are now being formalised thanks to the government’s efforts in this direction. This will usher in better job and social security for the labour force. It will help the labour force in building up savings for old age. The data from EPFO reflects this formalisation of existing jobs. It does not necessarily indicate the creation of new jobs.
Further, there is no need to discount the data by 20 per cent because these are now Aadhaar-linked and it is unlikely to double-count job-hoppers. It is only the ESIC data that is not completely free of duplication.
CPHS shows that the recent anguish around jobs has hit youngsters hard. The labour participation rate (LPR) of the age group 15-24 declined systematically in every wave after demonetisation. Lack of jobs has kept these people away from labour markets.
The LPR of the 15-19 years group fell from 20 per cent during January-August 2016 to 9 per cent during 2017. LPR for the 20-24 years group fell from 46 per cent to 39 per cent during the same period. This fall in the LPR for these young age groups holds true across male and female members and also across rural and urban regions.
The fall in the LPR of the young age groups stabilised by the end of 2017. It has not recovered to its pre-demonetisation levels.
Bhalla has raised doubts about the very low LPR among women seen in the CPHS data. That the female labour participation rate is low is quite well- established in all surveys. The question is whether it can be as low as 12 per cent as given in the Statistical Profile based on CPHS. First, the female LPR estimated from CPHS was 16 per cent during January-August 2016. It fell after demonetisation to 12 per cent and has not recovered since then.
Second, Bhalla has not found any sampling or non-sampling problems with CPHS as he states that the sample is large enough at over 500,000 individuals and the question on employment/unemployment status is too simple to elicit an incorrect answer.
So Bhalla deduces: “The only manner in which such a large outsized anomaly can be obtained is via incorrect weights.’’ But, why is that an anomaly? And, why are those weights incorrect? They are the same weights that were used to generate the estimate of 12 million jobs that were happily used by Bhalla to build up the claim of 15 million jobs being created in 2017.
Weights are not arbitrary adjustments that can be used to derive desired results. They are determined by the survey design of any complex survey. CPHS is a complex survey involving multi-stage stratification. CMIE has described the survey design in detail and it has provided weights against each sample household and each member in the survey. It has released the full R-code used to generate all estimates. All the record-level data is also available.
We will welcome criticism based on an examination of these. But, a mere comment that the weights are incorrect is indeed very much incorrect.
http://indianexpress.com/article/opinion/columns/pm-narendra-modi-india-job-growth-unemployment-rate-economy-demonetisation-bjp-5157708/